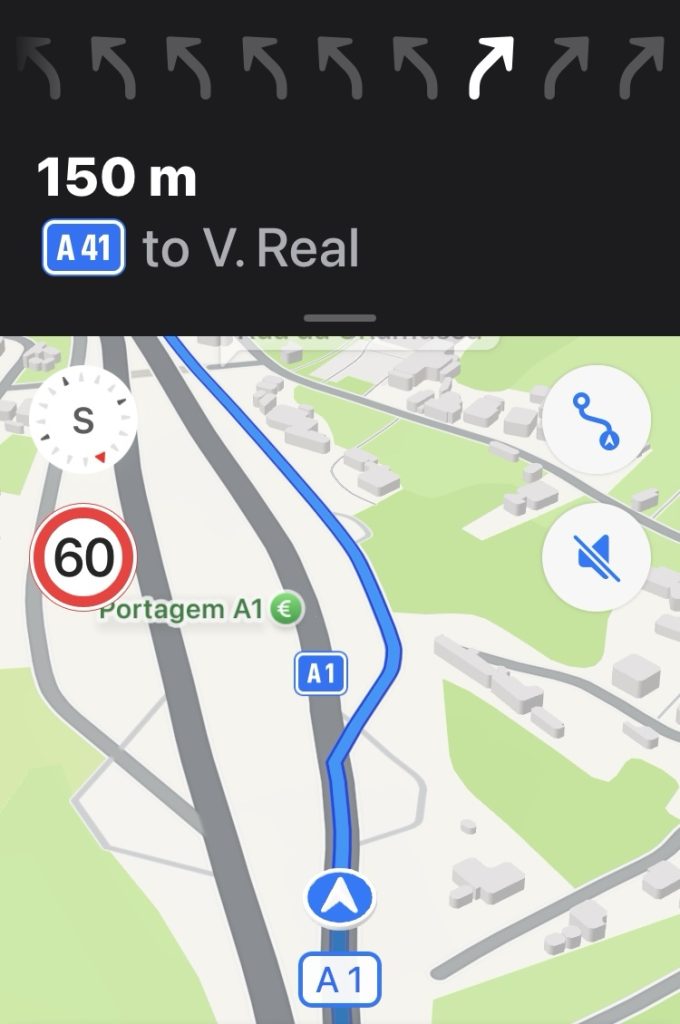
Lanes
Posted by Michael in hardware on Wednesday, July 1st
Not really surprising considering the fact that Portugal charges you for using the highway. The amount of lanes still looks impressive when approaching.
One Page
Posted by Michael in hardware on Monday, June 29th
We saw rather unusual fireworks. It was organized by BABELL and called One Page.


It was 4 drone launched images. Followed by a final ground (or river) launched part.

Revisiting the Planet
Posted by Alex in micCheck on Sunday, June 28th
We’ve been running our blog aggregation at lisas.de with a WordPress-based solution using the long-obsolete feed-pull plugin for ages. After receiving complaints that the cron hook for the plugin was pinging other hosts, I decided it was time to replace our aggregation solution (again).
So, welcome to the new LUGES Planet! We now have a few lines of Python (forked off of hugo-planet) to aggregate the blogs into Markdown using feedparser and render them to static HTML using the Hugo static site generator.
Supermarkets are prepared as well
Posted by Michael in hardware on Sunday, June 21st
Since the old tradition is to hit each other on the head on São João, there are offers of all size and color. The real tradition is to use a flower of leek to touch other people’s head.

Preparing for Festa de São João do Porto
Posted by Michael in hardware on Tuesday, June 2nd
On 24th of June we celebrate Festa de São João do Porto. The city starts preparing. First step is the electrical power supply.

Allowed names in Portugal
Posted by Michael in hardware on Tuesday, June 25th
Something I learned today: in Portugal there exists a list of allowed names. It contains more than 80 pages. More female than male names. The gender is also clearly assigned. Of course there are possibilities for exceptions. But if both parents are of Portuguese origin the kid will end up with one of the names from the list. There is not much variation related to the spelling.
But: Itâ€

Colors
Posted by Michael in hardware on Thursday, April 18th

Dom Pedro V
Posted by Michael in hardware on Saturday, April 6th
Dom Pedro V who was one of the kings of Portugal is also the eponym of the street in Porto we live in.

We found him also in the Monte Palace Tropical Garden. Not to be confused with the botanical garden.
The display is on the typical Portuguese tiles called Azulejo.
Guess the airport
Posted by Michael in hardware on Wednesday, April 3rd
We were on vacation. When returning we had this view from the balcony. Hint: Not many runways are trapped between the airport building and the mountains.

Check here if your guess was correct.
A bug in the wild
Posted by Michael in hardware on Tuesday, January 23rd
The snack vending machine in office got an update for cashless payment. And it looks like it also needs a software update.

Adventures hike in the neighborhood
Posted by Michael in hardware on Wednesday, January 17th
We went to the Serra de Midões e de Pias just 20 minutes from home.

and did a relatively short tour mostly along the Rio de Ferreira.
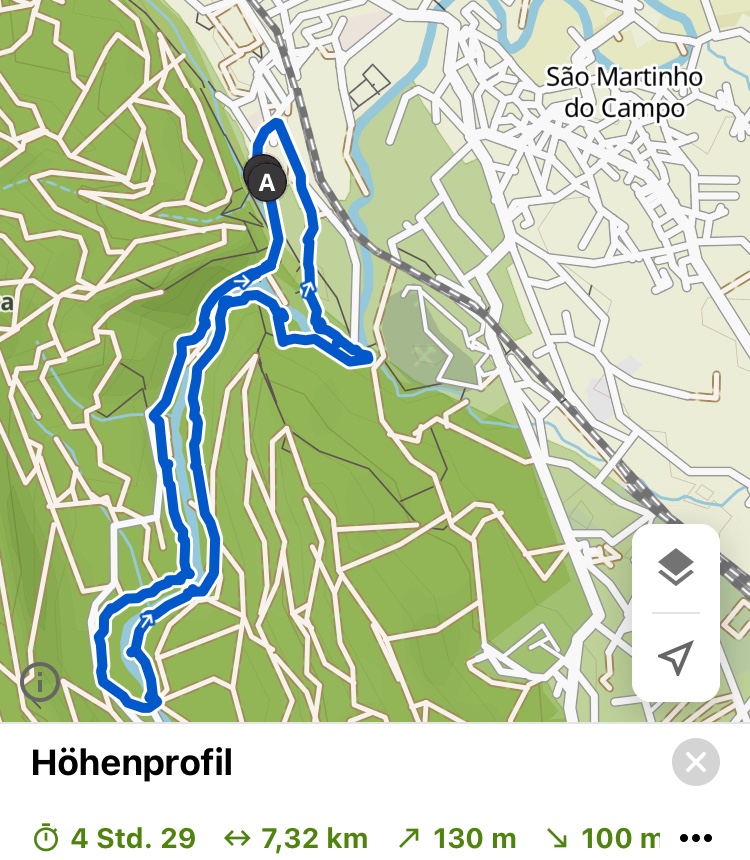
On the komoot map it looked initially like we could cross the river and take shortcut. But it turned out that this is only possible in summer. The river crossings were not possible with the amount of water in the river. So towards the end we had to climb a rather steep path. For the spoiled German member of the Schwarzwaldverein - used to having clear markings and walkable paths everywhere - it was a learning. Nevertheless a nice tour and on the way we found some nice places to rest and with a good view.