
Lazy Process Migration
Process Migration
Using CRIU it is possible to checkpoint/save/dump the state of a process into a set of files which can then be used to restore/restart the process at a later point in time. If the files from the checkpoint operation are transferred from one system to another and then used to restore the process, this is probably the simplest form of process migration.
Source system:
- criu dump -D /checkpoint/destination -t PID
- rsync -a /checkpoint/destination destination.system:/checkpoint/destination
Destination system:
- criu restore -D /checkpoint/destination
For large processes the migration duration can be rather long. For a process using 24GB this can lead to migration duration longer than 280 seconds. The limiting factor in most cases is the interconnect between the systems involved in the process migration.
Optimization: Pre-Copy
One existing solution to decrease process downtime during migration is pre-copy. In one or multiple runs the memory of the process is copied from the source to the destination system. With every run only memory pages which have change since the last run have to be transferred. This can lead to situations where the process downtime during migration can be dramatically decreased.
This depends on the type of application which is migrated and especially how often/fast the memory content is changed. In extreme cases it was possible to decrease process downtime during migration for a 24GB process from 280 seconds to 8 seconds with the help of pre-copy.
This approach is basically the same if migrating single processes (or process groups) or virtual machines.
It Always Depends On…
Unfortunately pre-copy optimization can also lead to situations where the so called optimized case with pre-copy can require more time than the unoptimized case:
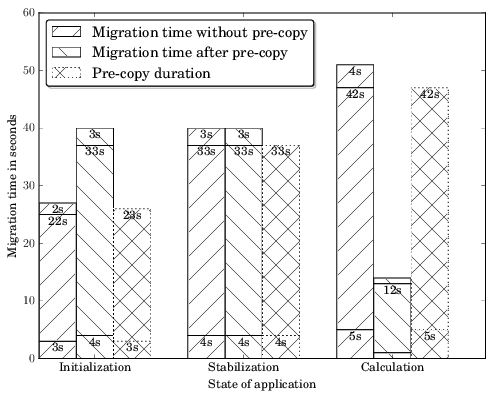
In the example above a process has been migrated during three stages of its lifetime and there are situations (state: Calculation) where pre-copy has enormous advantages (14 seconds with pre-copy and 51 seconds without pre-copy) but there are also situations (state: Initialization) where the pre-copy optimization increases the process downtime during migration (40 seconds with pre-copy and 27 seconds without pre-copy). It depends on the memory change rate.
Optimization: Post-Copy
Another approach to reduce the process downtime during migration is post-copy. The required memory pages are not dumped and transferred before restoring the process but on demand. Each time a missing memory page is accessed the migrated process is halted until the required memory pages has been transferred from the source system to the destination system:
![]()
Thanks to userfaultfd this approach (or optimization) can be now integrated into CRIU. With the help of userfaultfd it is possible to mark memory pages to be handled by userfaultfd. If such a memory page is accessed, the process is halted until the requested page is provided. The listener for the userfaultfd requests is running in user-space and listening on a file descriptor. The same approach has already been implemented for QEMU.
Enough Theory
With all the background information on why and how the initial code to restore processes with userfaultfd support has been merged into the CRIU development branch: criu-dev. This initial implementation of lazy-pages support does not yet support lazy process migration between two hosts, but with the upstream merged patches it is at least possible to checkpoint a process and to restore the process using userfaultfd. A lazy restore consists of two parts. The usual ‘criu restore‘ part and an additional, what we call uffd daemon, ‘criu lazy-pages‘ part. To better demonstrate the advantages of a lazy restore there are patches to enhance crit (CRiu Image Tool) to remove pages which can be restored with userfaultfd from a checkpoint directory. Using a test case which allocates about 200MB of memory (and which writes one byte in each page over and over) requires after being dumped about 200MB. Using the mentioned crit enhancement make-lazy reduces the size of the checkpoint down to 116KB:
$ crit make-lazy /tmp/checkpoint/ /tmp/lazy-checkpoint
$ du -hs /tmp/checkpoint/ /tmp/lazy-checkpoint
201M /tmp/checkpoint
116K /tmp/lazy-checkpoint
With this the data which actually has to be transferred during process downtime is drastically reduced and the required memory pages are inserted in the restored process on demand using userfaultfd. Restoring the checkpointed process using lazy-restore would look something like this:
First the uffd daemon:
$ criu lazy-pages -D /tmp/checkpoint --address /tmp/userfault.socket
And then the actual restore:
$ criu restore -D /tmp/lazy-checkpoint --lazy-pages --address /tmp/userfault.socket
The socket specified with --address is used to exchange information about the restored process required by the uffd daemon. Once criu restore has done all its magic to restore the process except restoring the lazy memory pages, the process to be restored is actually started and runs until the first userfaultfd handled memory page is accessed. At that point the process hangs and the uffd daemon gets a message to provide the required memory pages. Once the uffd daemon provides the requested memory page, the restored process continues to run until the next page is requested. As potentially not all memory pages are requested, as they might not get accessed for some time, the uffd daemon starts to transfer unrequested memory pages into the restored process so that the uffd daemon can shut down after a certain time.